GoSpider
High-performance concurrent web crawler in Go that converts thousands of web pages to Markdown in minutes.
I worked on this because I wanted to learn Go and scratch my own itch with scraping sites on a large scale. Yes i stole the name from the other gospider
The result was a high-performance, concurrent web crawler written in Go that implemented a producer-consumer architecture around Go’s core concurrency primitives - goroutines, buffered channels, and thread-safe maps.
The architecture centered on a 10,000-URL buffered queue that fed a configurable pool of worker goroutines, each independently fetching pages, extracting links, and converting HTML to Markdown. I paired this with a singleton HTTP client that maintained up to 500 connections per host, which kept throughput high even when hitting the same domain repeatedly. A separate pool of 16 dedicated file-writer goroutines with 1MB buffers handled all disk I/O in parallel, reducing filesystem overhead significantly.
I added proxy rotation with automatic validation and fallback to direct connections, domain-based rate limiting, and URL deduplication via in-memory hash maps for O(1) lookup. The crawler also extracted URLs from both the raw HTML and the converted Markdown output, which caught links that would otherwise be missed. Real-time monitoring reported URLs per second, queue depth, domain coverage, and success rates as the crawl ran.
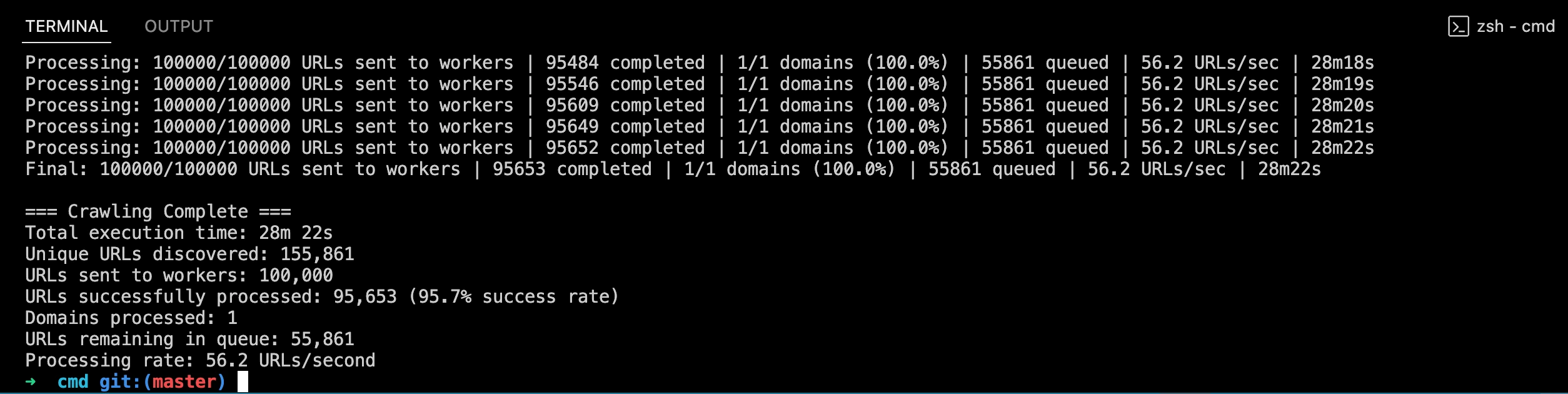
In practice, I was able to crawl and convert 100,000 URLs - parsing pages to Markdown and downloading assets - in under half an hour. The tool installs with a single go install command and exposes flags for worker count, domain and URL limits, proxy usage, image downloading, and verbosity, making it straightforward to tune for anything from a small site audit to a large-scale archiving job.